Recently I have been intrigued by the uses of Monte Carlo simulation and a myriad of their uses in probabilistic modelling techniques especially in NLP and social network modelling. I wanted to learn more about the monte carlo process and understand what are some of its basic uses. An often cited example people gave me was that of calculating the value of $\pi$ defining it as 4 times the area of a circle inscribed in a unit length square.
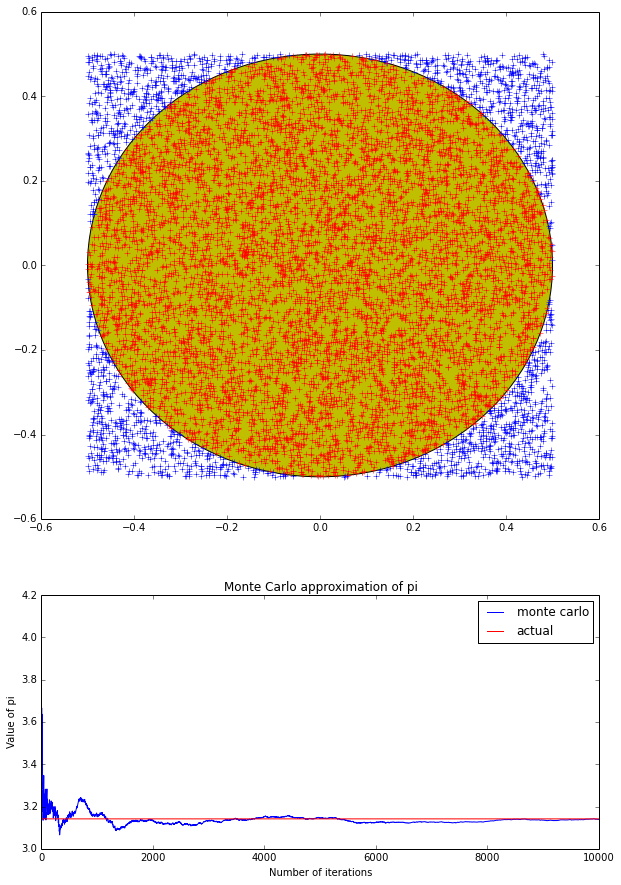
The below figure shows the distribution of randomly generated points falling inside and outside the circle. Also the other figure shows how with the greater number of iterations the value of pi converges to the actual value of pi.

The intuition behind the simulation process is that if we randomly generate points confined inside a square circumscribing a circle then the probability of the points falling inside the circle will be directly proportional to the area of the circle. Since the circle is inscribed in the square hence its radius is 0.5 and hence the area will be $\pi/4$. This ratio is also approximately equal to the number points randomly generated inside the square which fall inside the circle to the total generated points. The approximation will should converge to the value equal to pi if we have very large number of points ideally tending to infinite points inside the square.
The below code does the simulation and generates the above figures:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| """ | |
| Using Monte Carlo to find the value of pi. | |
| Intiution: Ratio of area of circle to area of uniq length squre it is inscribed it can be used to approximate pi. | |
| Area of circle = pi/4 | |
| Area of square = 1 | |
| Ratio = pi/4 | |
| Let us generate random points x,y inside the square. The probabilty of the point being inside circle is equal to the above ratio. | |
| Circle centered on origin. | |
| Given: -0.5 <= x,y <= 0.5 | |
| A point is inside circle if x**2 + y**2 <= 1/4 | |
| """ | |
| import matplotlib.pyplot as plt | |
| from matplotlib import gridspec | |
| import numpy as np | |
| plt.clf() | |
| MAXN = 10000 # Max number of iterations | |
| n = 1 # Current value of iteration | |
| n_arr = [] # Saving values of iterations | |
| pi_arr = [] # Approx values pi for given iteration | |
| n_circle = 0 # Number of points inside circle | |
| fig = plt.figure(figsize=(10,15)) | |
| gs = gridspec.GridSpec(2, 1, height_ratios=[2, 1]) | |
| ax = [plt.subplot(gs[0]),plt.subplot(gs[1])] | |
| # Create a circle just for representation | |
| circle = plt.Circle((0, 0), radius=0.5, fc='y') | |
| ax[0].add_patch(circle) | |
| # Run the simulation | |
| while n <= MAXN: | |
| p_color = 'b' # If point is outside circle mark it with blue color | |
| x = np.random.uniform(-0.5,0.5) | |
| y = np.random.uniform(-0.5,0.5) | |
| if (x**2 + y**2) <= 0.25: | |
| n_circle += 1 | |
| p_color = 'r' # If point is outside circle mark it with blue color | |
| ax[0].plot(x,y,p_color+'+') | |
| n_arr.append(n) | |
| pi_arr.append(n_circle*4.0/n) # Value of pi = 4*points in circle/points overall | |
| n+= 1 | |
| print n, n_circle, pi_arr[-1], n_arr[-1] | |
| ax[1].plot(n_arr,pi_arr,"b-",label="monte carlo") | |
| ax[1].plot(n_arr, np.pi*np.ones(len(n_arr)),"r-", label="actual") | |
| ax[1].legend() | |
| ax[1].set_xlabel("Number of iterations") | |
| ax[1].set_ylabel("Value of pi") | |
| plt.title("Monte Carlo approximation of pi") | |
The intriguing thing about this simulation is that using just 10000 points I am getting pretty good value of pi around 3.1392. This approximation however will change with each different run of the code as the randomly generated points change.
I am interested in learning more about such basic applications of monte carlo processes so that the understanding of the more complicated models is easier.



{kind=link}
You must be logged in to post a comment.